安装和设置 Aria2
# 使用 Homebrew 安装 aria2brew install aria2# 创建配置文件aria2.conf和空对话文件aria2.sessionmkdir ~/.aria2 && cd ~/.aria2touch aria2.conftouch aria2.session编辑配置文件aria2.conf
## '#'开头为注释内容, 选项都有相应的注释说明, 根据需要修改 #### 被注释的选项填写的是默认值, 建议在需要修改时再取消注释 #### 文件保存相关 ### 文件的保存路径(可使用绝对路径或相对路径), 默认: 当前启动位置dir=${HOME}/Downloads# 启用磁盘缓存, 0为禁用缓存, 需1.16以上版本, 默认:16Mdisk-cache=32M# 文件预分配方式, 能有效降低磁盘碎片, 默认:prealloc# 预分配所需时间: none < falloc ? trunc < prealloc# falloc和trunc则需要文件系统和内核支持# NTFS建议使用falloc, EXT3/4建议trunc, MAC 下需要注释此项#file-allocation=none# 断点续传continue=true## 下载连接相关 ### 最大同时下载任务数, 运行时可修改, 默认:5#max-concurrent-downloads=5# 同一服务器连接数, 添加时可指定, 默认:1, 最大值16max-connection-per-server=5# 最小文件分片大小, 添加时可指定, 取值范围1M -1024M, 默认:20M# 假定size=10M, 文件为20MiB 则使用两个来源下载; 文件为15MiB 则使用一个来源下载min-split-size=10M# 单个任务最大线程数, 添加时可指定, 默认:5#split=5# 分片选择算法,有助于视频的边下边播同时兼顾减少建立连接的次数stream-piece-selector=geom# 整体下载速度限制, 运行时可修改, 默认:0#max-overall-download-limit=0# 单个任务下载速度限制, 默认:0#max-download-limit=0# 整体上传速度限制, 运行时可修改, 默认:0#max-overall-upload-limit=0# 单个任务上传速度限制, 默认:0#max-upload-limit=0# 禁用IPv6, 默认:false#disable-ipv6=true# 连接超时时间, 默认:60timeout=60# 最大重试次数, 设置为0表示不限制重试次数, 默认:5max-tries=5# 设置重试等待的秒数, 默认:0#retry-wait=0## 进度保存相关 ### 日志文件log-level=noticelog=${HOME}/.aria2/aria2.log# 从会话文件中读取下载任务# 需提前创建一个空文件否则会报错input-file=${HOME}/.aria2/aria2.session# 在Aria2退出时保存`错误/未完成`的下载任务到会话文件save-session=${HOME}/.aria2/aria2.session# 定时保存会话, 0为退出时才保存, 需1.16.1以上版本, 默认:0save-session-interval=60# 强制保存会话, 即使任务已经完成, 默认:false# 较新的版本开启后会在任务完成后依然保留.aria2文件#force-save=true## RPC相关设置 ### 启用RPC, 默认:falseenable-rpc=true# 允许所有来源, 默认:falserpc-allow-origin-all=true# 允许非外部访问, 默认:falserpc-listen-all=true# RPC监听端口, 端口被占用时可以修改, 默认:6800rpc-listen-port=6800# 设置的RPC授权令牌# 此处使用`openssl rand -base64 32`命令生成<TOKEN>rpc-secret=<TOKEN># 是否启用 RPC 服务的 SSL/TLS 加密,# 启用加密后 RPC 服务需要使用 https 或者 wss 协议连接#rpc-secure=true# 在 RPC 服务中启用 SSL/TLS 加密时的证书文件,# 使用 PEM 格式时,您必须通过 --rpc-private-key 指定私钥#rpc-certificate=/path/to/certificate.pem# 在 RPC 服务中启用 SSL/TLS 加密时的私钥文件#rpc-private-key=/path/to/certificate.key## HTTP 设置 ### 自定义 User Agentuser-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.85 Safari/537.36## BT/PT下载相关 ### 当下载的是一个种子(以.torrent结尾)时, 自动开始BT任务, 默认:truefollow-torrent=true# BT监听端口, 当端口被屏蔽时使用, 默认:6881-6999listen-port=6881-6999# 单个种子最大连接数, 默认:55#bt-max-peers=55### DHT 功能, 仅对 BT 生效, PT 无效#### 打开 DHT (IPv4) 功能enable-dht=true# 打开 DHT (IPv6) 功能enable-dht6=true# DHT网络监听端口, 默认:6881-6999dht-listen-port=6881-6999# 本地节点查找bt-enable-lpd=true# 种子交换enable-peer-exchange=true# DHT (IPv4) 路由表文件路径dht-file-path=${HOME}/.aria2/dht.dat# DHT (IPv6) 路由表文件路径dht-file-path6=${HOME}/.aria2/dht6.dat# 客户端伪装, PT需要peer-id-prefix=-UT341-peer-agent=uTorrent/341(109279400)(30888)# 同一服务器连接数# 每个种子限速, 对少种的PT很有用, 默认:50K#bt-request-peer-speed-limit=50K# 当种子的分享率达到这个数时, 自动停止做种, 0为一直做种, 默认:1.0seed-ratio=0# BT校验相关, 默认:true#bt-hash-check-seed=true# 继续之前的BT任务时, 无需再次校验, 默认:falsebt-seed-unverified=true# 保存磁力链接元数据为种子文件(.torrent文件), 默认:falsebt-save-metadata=true# BT 服务器地址# 逗号分隔的 BT 服务器地址. 如果服务器地址在 --bt-exclude-tracker 选项中, 其将不会生效.bt-tracker=udp://tracker.coppersurfer.tk:6969/announce,udp://tracker.leechers-paradise.org:6969/announce,udp://tracker.opentrackr.org:1337/announce,udp://p4p.arenabg.com:1337/announce,udp://9.rarbg.to:2710/announce,udp://9.rarbg.me:2710/announce,udp://tracker.internetwarriors.net:1337/announce,udp://exodus.desync.com:6969/announce,udp://tracker.tiny-vps.com:6969/announce,udp://tracker.moeking.me:6969/announce,udp://retracker.lanta-net.ru:2710/announce,udp://open.stealth.si:80/announce,udp://open.demonii.si:1337/announce,udp://tracker.torrent.eu.org:451/announce,udp://tracker.cyberia.is:6969/announce,udp://denis.stalker.upeer.me:6969/announce,udp://tracker3.itzmx.com:6961/announce,udp://ipv4.tracker.harry.lu:80/announce,udp://valakas.rollo.dnsabr.com:2710/announce,udp://tracker.nyaa.uk:6969/announce,udp://retracker.netbynet.ru:2710/announce,udp://opentor.org:2710/announce,udp://explodie.org:6969/announce,http://explodie.org:6969/announce,udp://zephir.monocul.us:6969/announce,udp://xxxtor.com:2710/announce,udp://tracker.zum.bi:6969/announce,udp://tracker.yoshi210.com:6969/announce,udp://tracker.uw0.xyz:6969/announce,udp://tracker.sbsub.com:2710/announce,udp://tracker.lelux.fi:6969/announce,udp://tracker.iamhansen.xyz:2000/announce,udp://tracker.filemail.com:6969/announce,udp://tracker.dler.org:6969/announce,udp://retracker.sevstar.net:2710/announce,udp://retracker.akado-ural.ru:80/announce,udp://open.nyap2p.com:6969/announce,udp://chihaya.toss.li:9696/announce,udp://bt2.archive.org:6969/announce,udp://bt1.archive.org:6969/announce,udp://bt.okmp3.ru:2710/announce,https://tracker.nanoha.org:443/announce,http://tracker.torrentyorg.pl:80/announce,http://tracker.opentrackr.org:1337/announce,http://tracker.internetwarriors.net:1337/announce,http://tracker.bt4g.com:2095/announce,http://t.nyaatracker.com:80/announce,http://retracker.sevstar.net:2710/announce,http://pow7.com:80/announce,http://mail2.zelenaya.net:80/announce,http://h4.trakx.nibba.trade:80/announce,udp://tracker4.itzmx.com:2710/announce,udp://tracker2.itzmx.com:6961/announce,udp://tracker.zerobytes.xyz:1337/announce,udp://tracker.swateam.org.uk:2710/announce,udp://tr.bangumi.moe:6969/announce,udp://qg.lorzl.gq:2710/announce,udp://opentracker.i2p.rocks:6969/announce,udp://bt2.54new.com:8080/announce,https://tracker.opentracker.se:443/announce,https://tracker.lelux.fi:443/announce,http://www.loushao.net:8080/announce,http://vps02.net.orel.ru:80/announce,http://tracker4.itzmx.com:2710/announce,http://tracker3.itzmx.com:6961/announce,http://tracker2.itzmx.com:6961/announce,http://tracker1.itzmx.com:8080/announce,http://tracker01.loveapp.com:6789/announce,http://tracker.zerobytes.xyz:1337/announce,http://tracker.yoshi210.com:6969/announce,http://tracker.nyap2p.com:8080/announce,http://tracker.lelux.fi:80/announce,http://tracker.bz:80/announce,http://opentracker.i2p.rocks:6969/announce,http://open.acgnxtracker.com:80/announce# BT 排除服务器地址bt-exclude-tracker=# 启用后台进程daemon=false# 部分事件hook, 调用第三方命令:/path/to/command# BT下载完成(如有做种将包含做种,如需调用请务必确定设定完成做种条件)on-bt-download-complete=${HOME}/.aria2/download-complete-hook.sh# 下载完成on-download-complete=${HOME}/.aria2/download-complete-hook.sh# 下载错误on-download-error=# 代理 仅支持 HTTP 协议#all-proxy=http://127.0.0.1:1087本人设置文件:
- 默认开启 RPC 模式
- 已设置RPC授权令牌, 详见设置文件注释
- 已经添加 BT tracker,更多详见 XIU2/TrackersListCollection
设置为macOS的开机启动
参考: 控制macOS的开机启动
创建用户启动文件
touch ~/Library/LaunchAgents/aria2.plist写入如下
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd"><plist version="1.0"><dict> <key>KeepAlive</key> <true/> <key>Label</key> <string>aria2</string> <key>ProgramArguments</key> <array> <string>/usr/local/bin/aria2c</string> </array> <key>RunAtLoad</key> <true/> <key>WorkingDirectory</key> <string>${HOME}/Downloads</string></dict></plist>注意: 修改
WorkingDirectory目录
# 检查plist语法是否正确plutil ~/Library/LaunchAgents/aria2.plist# 修改文件权限chmod 644 ~/Library/LaunchAgents/aria2.plist添加并启用自启动项
# 添加自启动项: aria2launchctl load ~/Library/LaunchAgents/aria2.plist# 删除自启动项: aria2launchctl unload ~/Library/LaunchAgents/aria2.plist# 启动服务: aria2launchctl start aria2# 停止服务: aria2launchctl stop aria2更多
launchctl使用方法, 详见命令手册
可使用killall aria2c结束进程, 并会自动重启进程
添加自动更新BT tracker功能
创建trackers-list-aria2.sh脚本
脚本内容如下:
#!/bin/bash#trackers-list-aria2.sh# aria2 设置文件路径CONF=${HOME}/.aria2/aria2.conf#设置选择的 trackerlist (可选 all_aria2.txt, best_aria2.txt, http_aria2.txt)trackerfile=all_aria2.txt#downloadfile=https://raw.githubusercontent.com/ngosang/trackerslist/master/${trackerfile}downloadfile=https://trackerslist.com/${trackerfile}list=$(curl -fsSL ${downloadfile})if ! grep -q "bt-tracker" "${CONF}" ; then echo -e "\033[34m==> 添加 bt-tracker 服务器信息......\033[0m" echo -e "\nbt-tracker=${list}" >> "${CONF}"else echo -e "\033[34m==> 更新 bt-tracker 服务器信息.....\033[0m" sed -i '' "s@bt-tracker.*@bt-tracker=${list}@g" "${CONF}"fi## 重启 aria2 服务echo -e "\033[34m==> 停止 aria2 服务......\033[0m"launchctl stop aria2echo -e "\033[34m==> 启动 aria2 服务......\033[0m"launchctl start aria2脚本放置到 ~/.aria2/,并设置运行权限:
chmod +x ~/.aria2/trackers-list-aria2.sh设置任务计划程序 实现自动更新
参考:
编译当前用户任务计划
crontab -e在打开的vi中 键入如下, 并使用:wq命令保存退出, 可用crontab -l查看当前用户任务计划
0 18 * * * ~/.aria2/trackers-list-aria2.sh或者 直接
(crontab -l 2&> /dev/null; echo "0 18 * * * ~/.aria2/trackers-list-aria2.sh") | crontab以上表示: 每天下午 6 点自动更新
BT tracker(并重启aria2服务)
更多crontab时间的设定详见: 这里
取消计划任务
crontab -e然后手动删除, 或者
crontab -l 2&> /dev/null| sed "/trackers-list-aria2.sh/d" | crontab
添加下载通知
最终效果:当下载完成会在屏幕右上角弹出一个提示框显示具体下载完成的文件名,同时中文语音播报:“有个文件下载完成,请查收!”

创建download-complete-hook.sh脚本
参考:
脚本内容如下:
#!/bin/sh# 给aria2 RPC添加一个下载完成通知 for macOS# 最终效果:当下载完成会在屏幕右上角弹出一个提示框显示具体下载完成的文件名,# 同时中文语音播报:“有个文件下载完成,请查收!”# 变量 3 表示下载完成文件的路径# 具体提示框设置可参考`https://code-maven.com/display-notification-from-the-mac-command-line`。# 不支持设置自定义图标fname=`basename $3`osascript <<EOFdisplay notification "$fname 已经下载完成!" with title "【下载完成】"say "有个文件下载完成,请查收!"EOF将脚本放置到 ~/.aria2/,并设置运行权限:
chmod +x ~/.aria2/download-complete-hook.sh添加 Hook 设置
参考:
在 aria2 设置文件.aria2.conf加入如下:
# BT下载完成(如有做种将包含做种,如需调用请务必确定设定完成做种条件)on-bt-download-complete=${HOME}/.aria2/download-complete-hook.sh# 下载完成on-download-complete=${HOME}/.aria2/download-complete-hook.shAria2 web UI
无需安装,直接使用浏览器打开: AriaNg版 UI
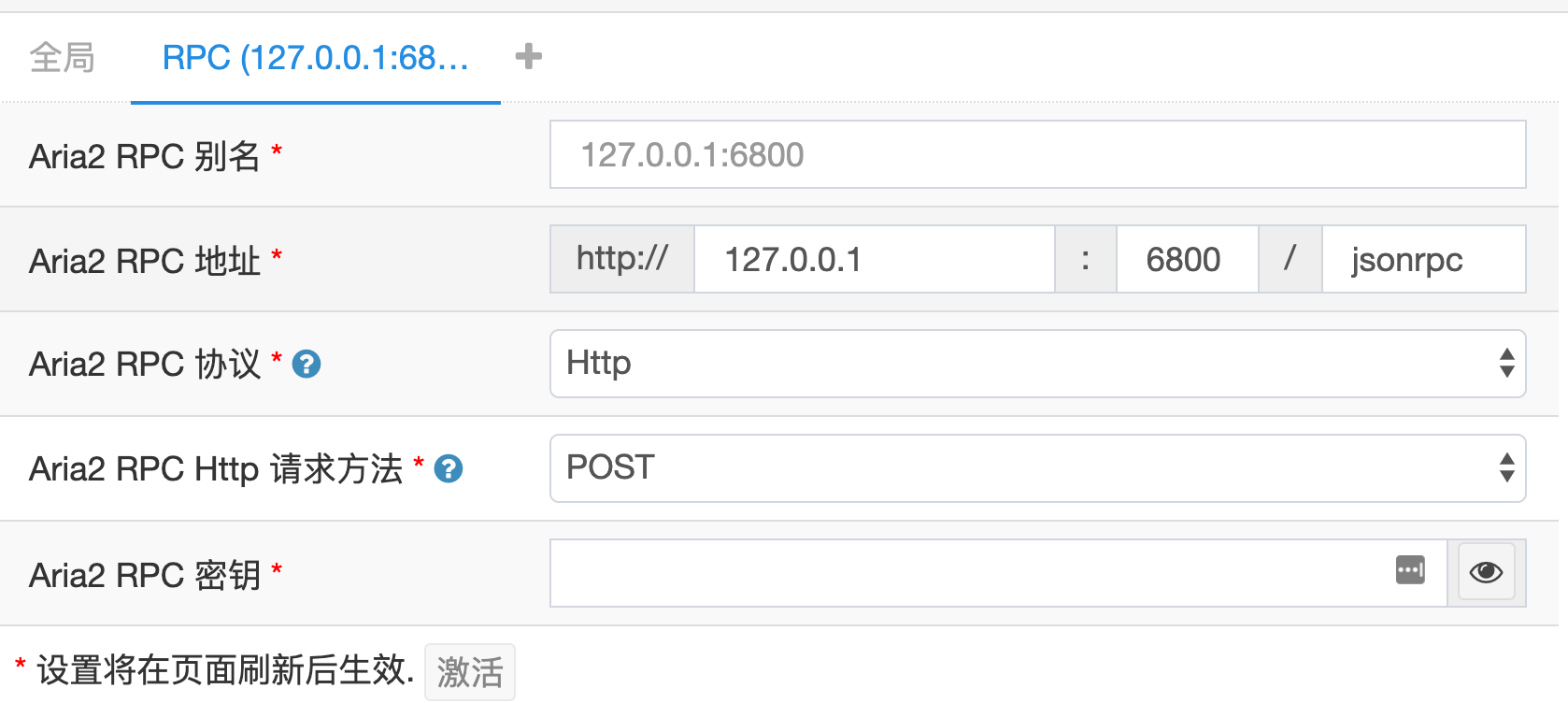
PRC 设置
根据 aria2 配置文件中的 PRC 相关设置项进行设置
安装浏览器下载插件
- 内置一个离线 AriaNg版 UI
- 整合右键下载菜单
内置的离线 AriaNg版也需要设置PRC,否则无法“导出到 ARIA2 RPC”。
以下内容仅供参考 现阶段实用性不大
百度云下载
安装 网盘助手
浏览器插件版
直接进入网盘助手主页,按浏览器不同下载并安装对应的插件
脚本版
网盘助手脚本,需要通过拓展 Violentmonkey 或者 Tampermonkey 等脚本管理器来启用
使用方法
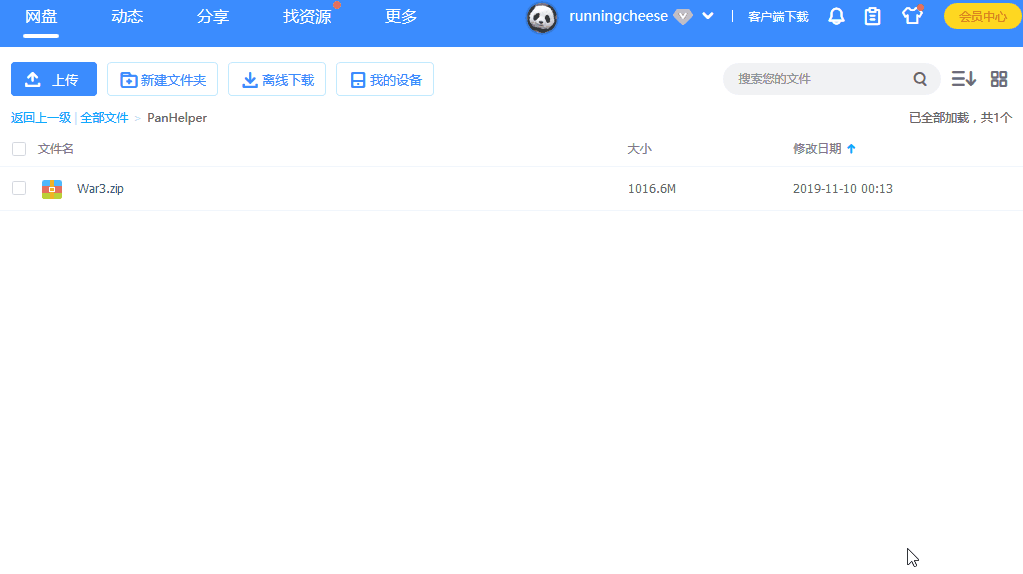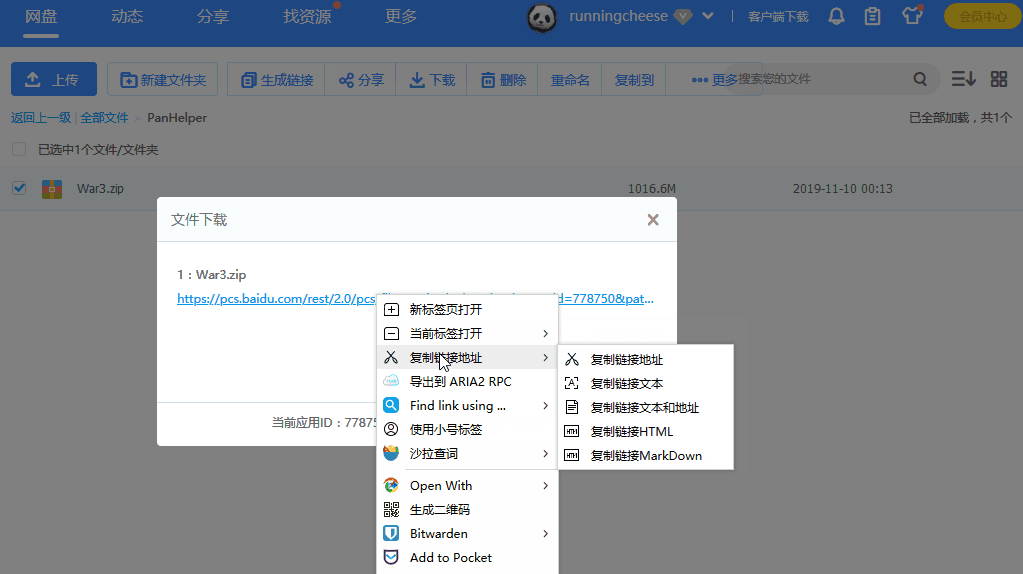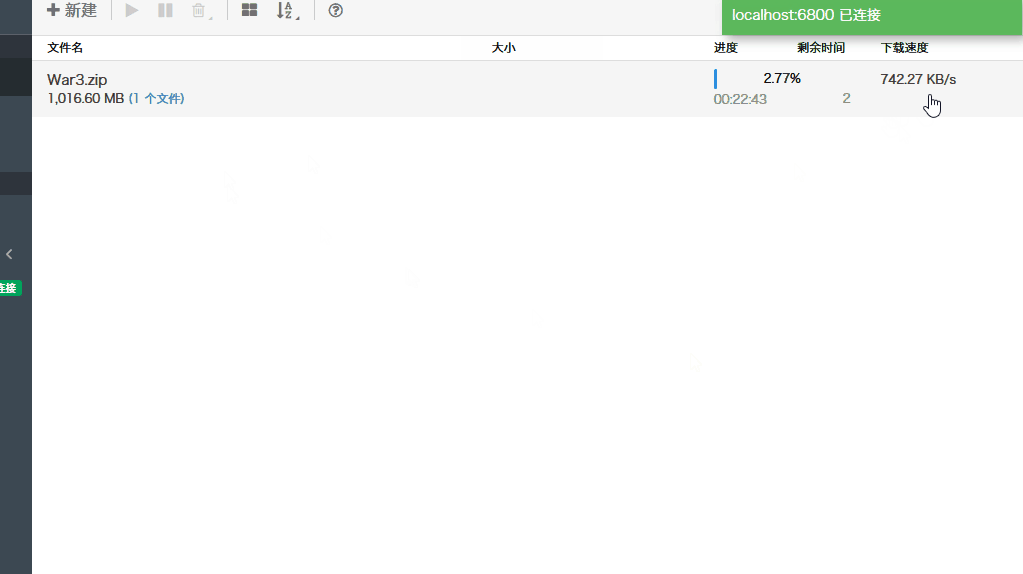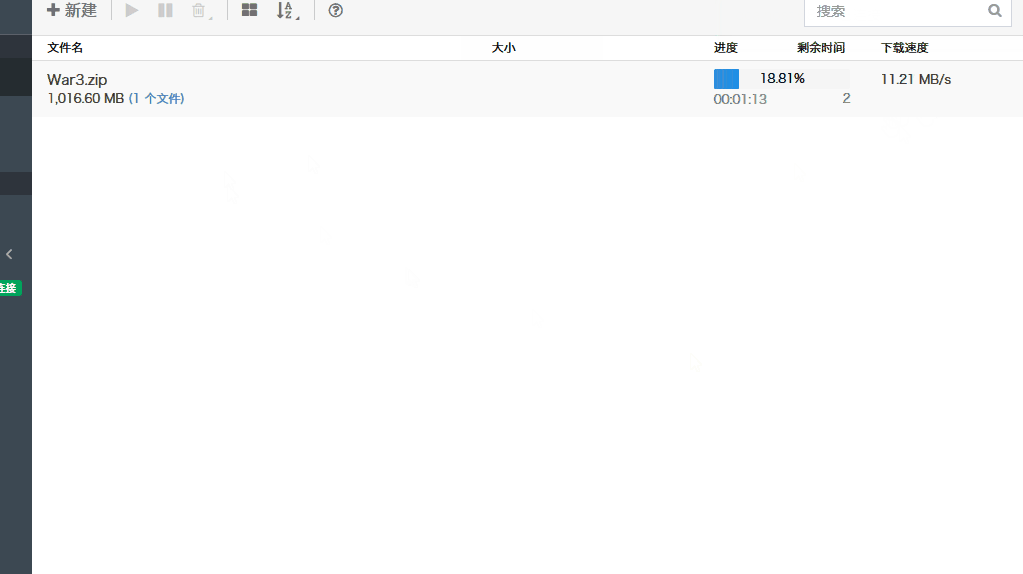
- 选择要下载的文件,点击页面里的 “生成链接” 来获取加速下载地址。
- 使用鼠标右键点击链接,选择“导出到 ARIA2 RPC”,然后确定下载。